This article is part of my highlights of the IEEE VIS 2020 conference. Of course, the talks I selected are those that lie closest to my own research; there were many more interesting presentations. I have provided links to the conference website and the presentations on YouTube, skipping ahead to the actual start.
This overview focuses on explainable artificial intelligence (XAI). As that topic forms the core of my research, I was delighted to listen to many inspiring talks about trust, expertise, different explanations types, etc. It was also reassuring that researchers are looking for methods to test explanations' effectiveness rigorously.
TREX: Workshop on TRust and EXpertise in Visual Analytics
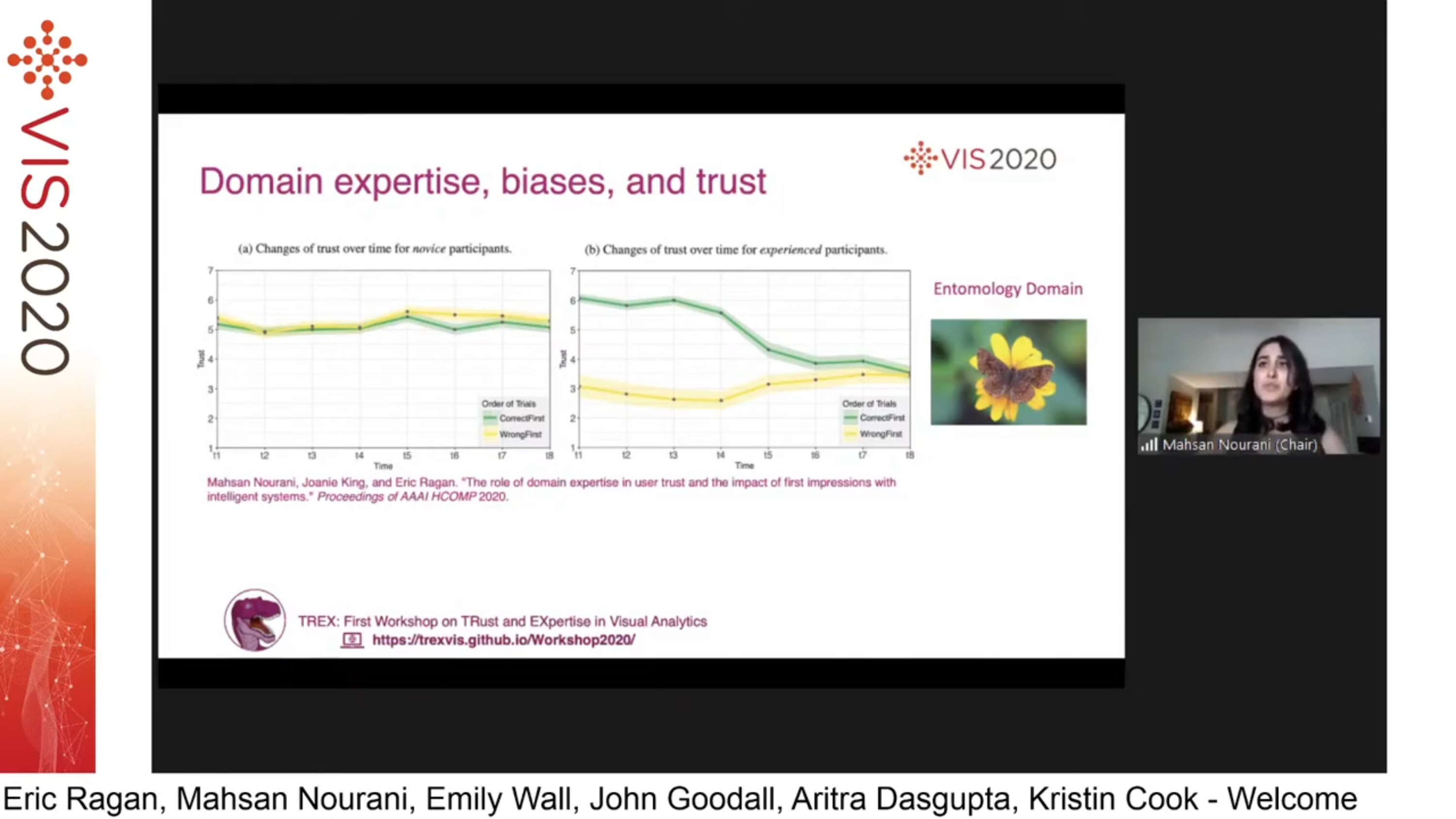
Talk 1. Opening by Mahsan Nourani. Users can build different mental models of an AI system, depending on whether they first see accurate or inaccurate examples. Users' expertise can also impact how their trust in AI systems evolves.
Talk 2. Measure Utility, Gain Trust: Practical Advice for XAI Researchers by Dustin Arendt. Trust is not a measure that should be maximised by design. Instead, researchers should focus on the utility of explanations by comparing a "human + machine + explanation" setting with "human + machine", "human only", and "machine only" settings. The paper contains very interesting use cases for measuring the utility of explanations.

Talk 3. Intelligibility Throughout the Machine Learning Life Cycle by Jenn Wortman Vaughan. Wonderful talk about a human-centred agenda for intelligibility in machine learning, discussing 3 focus points based on previous studies:
- Empirically testing the impact of system design on human behaviour: the visualisation community can help in how explanations are presented
- Intelligibility beyond the model, e.g. expectations about model performance and uncertainty
- Evaluating intelligibility with stakeholders: this is very hard and is a research agenda on its own beyond machine learning research

VISxAI: Visualization for AI Explainability
This associated event was packed with interesting examples of how visualisations can explain how AI algorithms work. One example reminded me of my healthcare-related highlights of IEEE VIS 2020: in Shared Interest: Human Annotations vs. AI Saliency by Angie Boggust, explanation regions outline which pixels are used to classify images, and this revealed that the appearance of dermatoscopic tools in images of melanoma always led to the melanoma being classified as benign.

Sense & Explainabilities
This session focused on how to make sense of machine learning outcomes with different kinds of explanations. My favourite talk was DECE: Decision Explorer with Counterfactual Explanations for Machine Learning Models by Furui Cheng. Their visual analytics system provides actionable and customisable explanations on an instance and subgroup level.

VDS: Visualization in Data Science
This associated event presented many interesting examples of how visualisation can give insights into data. I was particularly charmed by the 2 keynotes. Although the second is not really about XAI, I include it here as it shares a key message with the first: XAI and visualisation research should build more on theory.
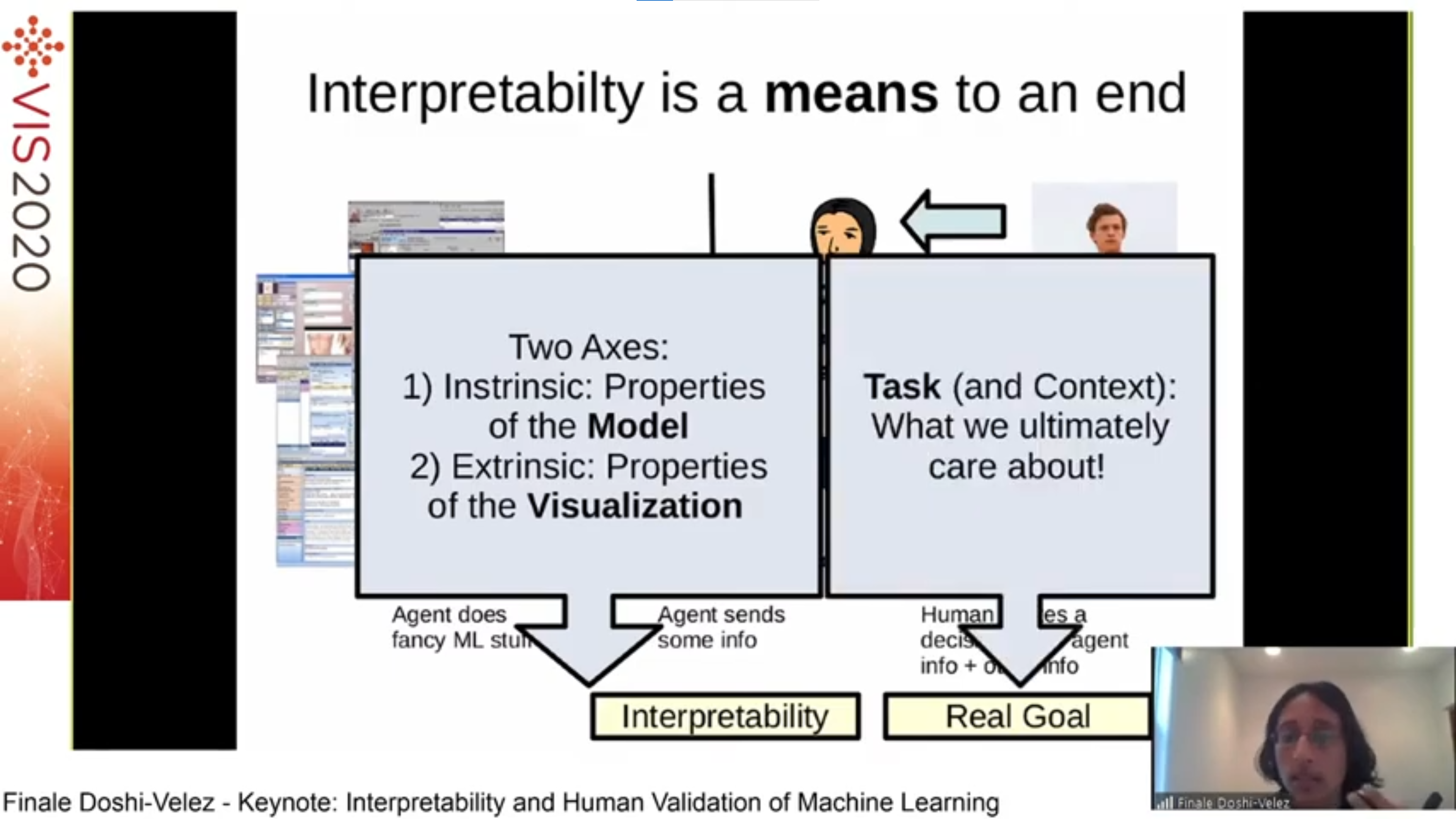
Keynote 1. Interpretability and Human Validation of Machine Learning by Finale Doshi-Velez. Interpretability is a means to an end (e.g. in healthcare, the end goal is to better treat patients) and should be evaluated more rigorously in the context of clear tasks. Several studies illustrate how that can be done concretely.
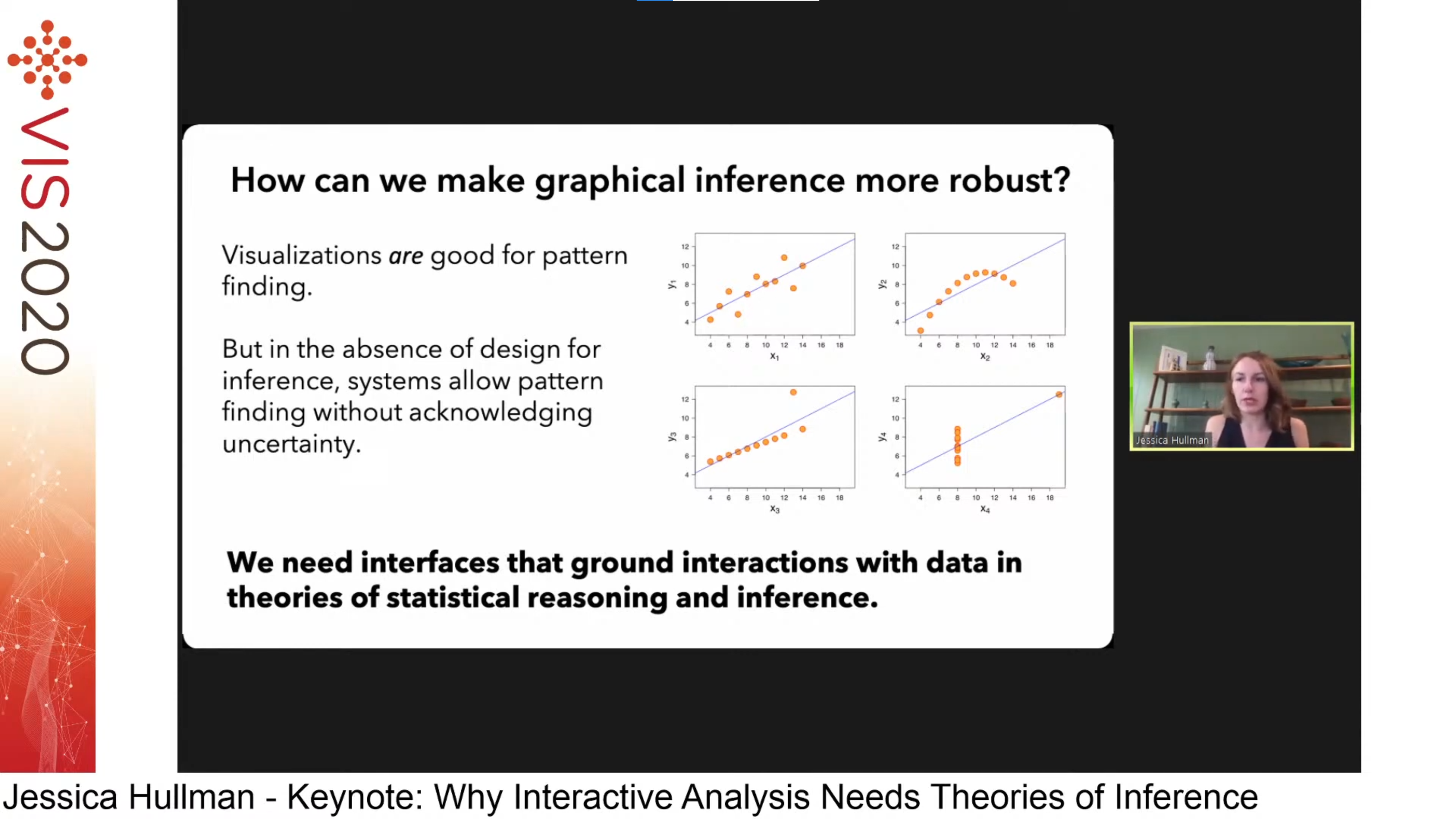
Keynote 2. Why Interactive Analysis Needs Theories of Inference by Jessica Hullman. Simply exposing patterns in data with visualisations is not sufficient: visualisations are not the end goal; they should support inference-making. This philosophy is illustrated by many previous studies on Bayesian model checking and Bayesian cognition.