My paper for the TREX 2021 workshop at the IEEE VIS 2021 conference, the largest conference on information visualisation. The paper is about how domain expertise influences people's trust in prediction models. Read it on ResearchGate, arXiv, IEEE Xplore, or download the pdf underneath.

Abstract
People's trust in prediction models can be affected by many factors, including domain expertise like knowledge about the application domain and experience with predictive modelling. However, to what extent and why domain expertise impacts people's trust is not entirely clear. In addition, accurately measuring people's trust remains challenging. We share our results and experiences of an exploratory pilot study in which four people experienced with predictive modelling systematically explore a visual analytics system with an unknown prediction model. Through a mixed-methods approach involving Likert-type questions and a semi-structured interview, we investigate how people's trust evolves during their exploration, and we distil six themes that affect their trust in the prediction model. Our results underline the multi-faceted nature of trust, and suggest that domain expertise alone cannot fully predict people's trust perceptions.
Prerecorded video (~10 mins)
Live video (~7 mins)
My presentation starts around 10.310s (watch on YouTube).
Preview (~30 secs)
Handouts

Transcript of the full video
Hi my name is Jeroen Ooge. I'm a PhD researcher at KU Leuven in Belgium and my supervisor is Katrien Verbert. I'm really excited that you are interested in my TREX workshop paper at VIS 2021 and as you can see its title is "Trust in prediction models: a mixed-methods pilot study on the impact of domain expertise". So let me tell you something about that.
Trust and XAI research in general often dichotomize the population in two groups. That is, on the one hand we have people who have expertise in something, for example predictive modeling, and this group is called the "experts". And then on the other hand we have the "non-experts" and those are people who are less experienced with that something. The research question then often becomes: are there differences between those two groups, or are there similarities within those groups? And I was particularly interested in whether I could indeed find similarities in a group of experts.
So that is why I collected four participants who were all experienced in predictive modeling. And the general idea of my study was to show them a quite simple visualization of a prediction model which became increasingly more complex and increasingly showed more information about the prediction outcomes. So I wanted to know two things. First, I was wondering whether these experts have similar trust levels and evolutions over several scenarios. And second, I was also wondering what actually influences the trust in the prediction model.
Of course, to make a fair comparison, to make fair statements, I needed a homogeneous group. So that is why I made sure that the four participants had a similar background. I chose an agrifood background because in agrifood there hasn't been a lot of research so far on visualizing uncertainty nor trust. And then I also had to make sure that the participants had sufficient expertise, and therefore I combined three scores. So first a self-reported score, and then a score based on their background and jargon use. Of course this jargon use already hints at a kind of interview but I will tell something more about that in a minute. First, I would like to give you some more details about the visual analytics system and the study design.
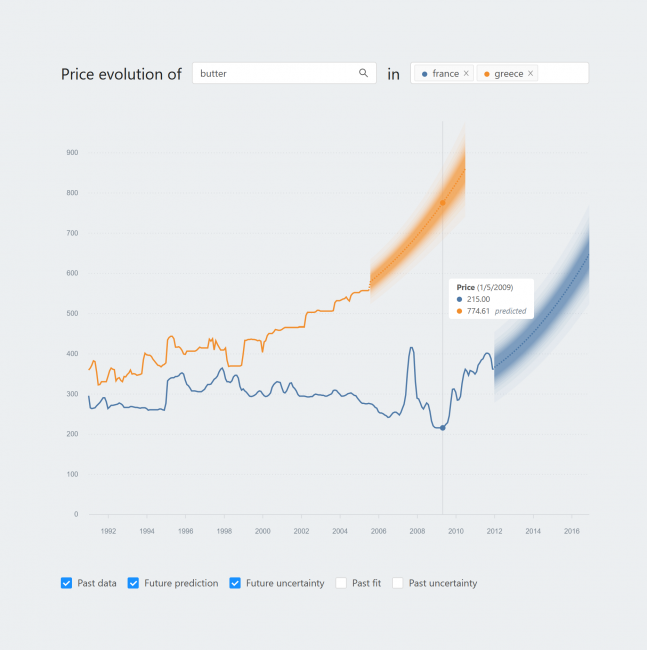
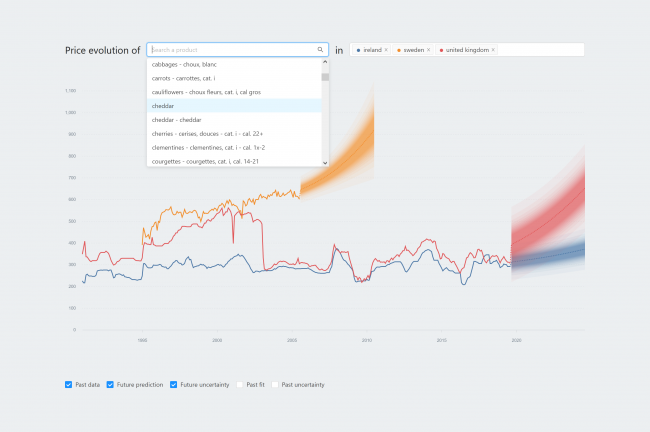
So participants went through eight scenarios in a quite simple visual analytics system that showed the price evolution of a specific product in one or two countries. So as you can see at the bottom of the visualization there were four check boxes that allowed to show more visual components First there is future prediction which is just a dashed line, then there's future uncertainty which is the colored bands, then there's a past fit which is again a dashed line, and then there is past uncertainty as well. Then, participants added a second country and went through the same four scenarios: first future prediction, then the future uncertainty, the past fit, and finally the past uncertainty.
So those were the eight scenarios. Then in each scenario, I measured trust in two ways. First qualitatively via a semi-structured interview in which I first asked participants to explore the visualization and just tell me what they saw in the visualization, what grabbed their attention. Then I also explicitly asked about trust and which parts of the visualization influenced their answers. Secondly, I measured trust quantitatively with four Likert-type questions: whether they were suspicious, whether they felt confident, whether they trusted the prediction model, and whether they felt that the prediction model was deceptive. So this rich mix of qualitative and quantitative data got a lot of results and I'm going to show you some of them now.
The first research question was: do experts have similar trust levels and evolutions over these eight scenarios for the unknown prediction model? And I have plotted the trust scores in this diagram over these eight scenarios. There are several things that you can notice here. First of all, if you look at setting 1 with one country, setting 2 with two countries, separately, you see that in general there's a non-decreasing trend. That means that people got more trust when they saw more visual components. Secondly, also when people went from scenario 4 to scenario 5 there was typically a quite drastic drop in trust. And finally, which is actually the most important here, is that there is a clear distinction between two groups of two people. So two people had quite high trust scores whereas the other two had low trust scores. And this quantitative result shows that the similar backgrounds and similar domain expertise alone could not predict the trust levels and trust evolutions. So of course this quantitative data alone cannot explain this distinction and this is where the qualitative data comes in.
The qualitative data is related to the second research question which was: what influences the experts' trust in an unknown prediction model? I did a thematic analysis of all the feedback that the participants gave and I found six trust themes. The first one is about their expectations about model outcomes. So when they observed something that violated their expectations, then typically their trust decreased whereas, conversely, if they saw something that agreed with their expectations then participants' trust increased. The second theme is understanding the prediction model which is about: how does a model work, what parameters does it take into account? Typically if they did not understand the production model, they had low trust. The third theme is: predictions need uncertainty. So most participants felt that uncertainty is a natural requirement in the context of a prediction and so when they also saw this uncertainty their trust typically increased.
The three last themes are quite self-explanatory so let me just cover them quickly. Developers of the prediction model: who developed it? Data provenance: is data accurate, where does it come from? And past performance of the prediction model: did the model perform well in the past? If yes, then in general trust increased. Of course this is just a brief summary of all the details that are in the paper so if you want some more insights then of course refer to the text.
To close the presentation, I will just give you some take-aways and there are actually four of them. The first two take-aways are rather related. The first is: an "expert" label does not say it all. And the second is: trust is multi-faceted. I feel like this is kind of stating the obvious. The "expert" label that we assigned to people, so their expertise, could not, as we saw in the quantitative results, could not predict or foresee their trust evolution and trust levels. And trust is multi-faceted. Of course trust is not this monolithic concept that is easy to measure. No, it's really complex, and we found six themes that affected trust. I think on a methodological level there is also two lessons here. The first one is about expertise. I think it's really important to measure expertise in different ways because a lot of studies in XAI just rely on one score, a self-reported score, but I think it's also important to take into account the background and the jargon use, which can be an implicit clue for the expertise of a person. And then second, if we want this jargon use, of course we need some qualitative data. Therefore I think it's often desirable to have this mixed-methods approach as in my study, especially in contexts about trust, which is really difficult. I think it's really important to really understand why people give a certain score quantitatively and really understand what changes their trust.
The third take-away is that dominant trust themes can evolve. Over these eight scenarios, the dominant trust themes were not fixed. For example, for participants 1 and 3, at the start, in the setting with one country, their understanding of the prediction model was quite low so they also had low trust but then when they went to the second setting their trust decreased even more because they saw something that violated their expectations.
And then the final take-away is that the trust themes that I presented before are not isolated at all: they're interconnected and I think the most interesting here is that themes 2 until 5 are all about transparency: understanding the model, seeing uncertainty, knowing something about the developers, knowing something about the data provenance, this is all about transparency. And I think this is really interesting for researchers who try to increase stress in the prediction model because it shows or suggests that if we increase transparency, which we do a lot in XAI, then we can also indirectly increase trust.
So that's about it for now. I really hope that you found this interesting. If you have some extra questions or you want some more details, some more insights, some more take-aways, then definitely read the paper or contact me via Twitter, email, LinkedIn.
I'm really looking forward to have a nice discussion on explainable AI, visual analytics, trust, and maybe we can also do something together in the future. Thanks a lot!